Backends for Frontends (BFF) architecture explained
At Ramsey Solutions, we've been working on adopting two architectural patterns in unison: Backends for Frontends (BFF) and micro-SPAs. This adoption effort was championed by one of our executive directors, Daniel Hopper, who illustrated to us how the two patterns could be used harmoniously. As one of the advocates for BFFs and micro-SPAs, I thought it fitting to write about them. While each pattern stands on its own, they can easily be joined together to create one powerhouse of an architecture.
Let's begin by discussing BFFs, and in my next post we'll talk about micro-SPAs.
The Backends for Frontends architecture was created by Sam Newman and first described in his 2015 book Building Microservices: Designing Fine-Grained Systems. He also describes the architecture in this post. Since then, BFFs have been adopted by many organizations, including SoundCloud, and a plethora of articles have been written about them.
To motivate the need for BFFs, we'll analyze a bookstore application which embodies a common software architecture lifecycle that many applications go through.
Bookstore: A case study
Let's say you run an online bookstore. The bookstore will work by keeping track of an inventory of available books, allowing customers to order books, allowing customers to write book reviews, and so on. When you first start the business, it makes sense to build it as a single, monolithic application with a single database to store everything. Your architecture looks like this:

As your business grows, so do your challenges. You realize you have way more reviews and orders than you do books, and the number of reviews being created is taxing your application and slowing the whole thing down. You can scale up the server that your application is running on, but the next size is quite expensive. You decide to split your application into several microservices that can be individually scaled horizontally which proves to be more cost efficient. Your architecture now looks like this:
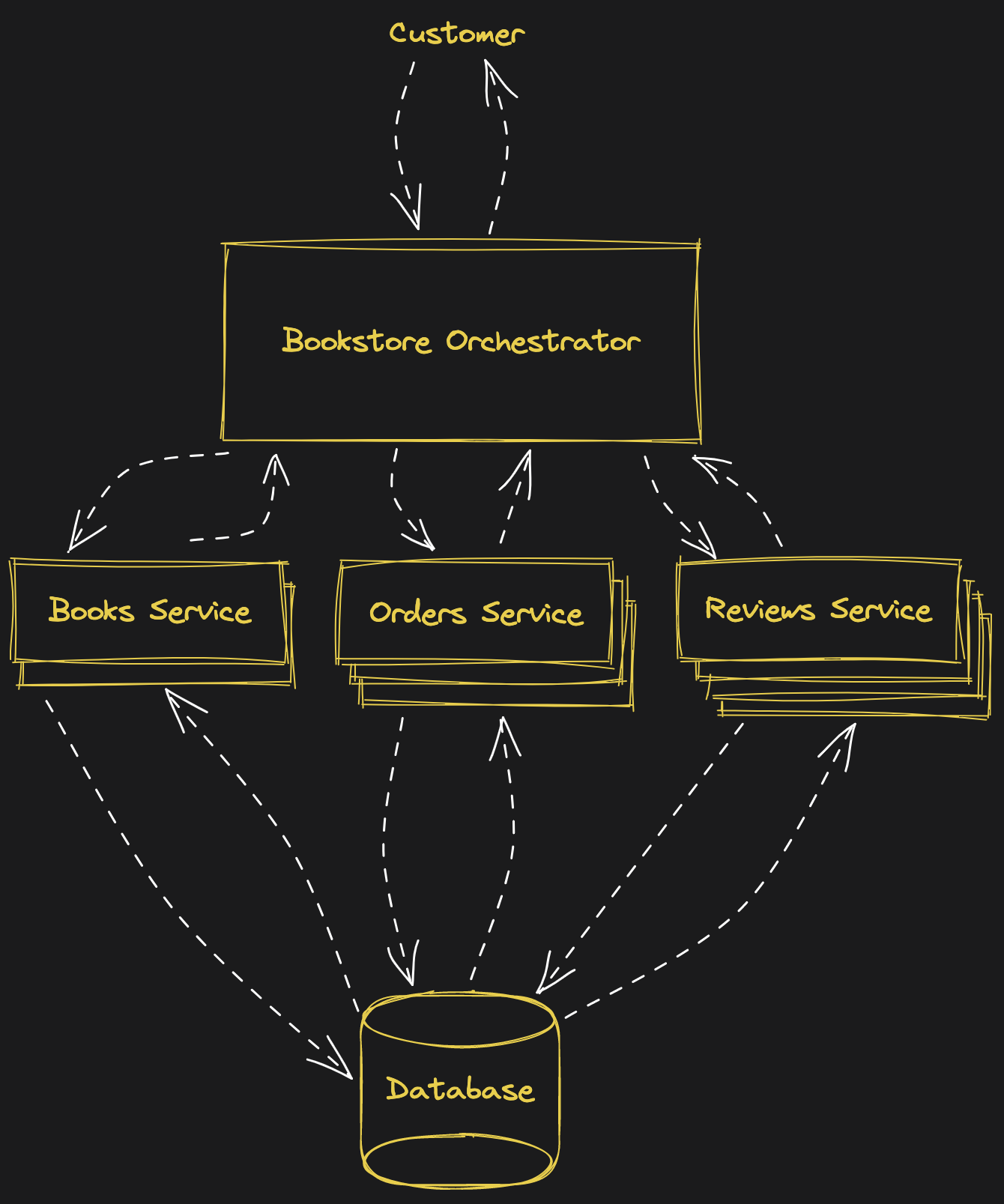
Your main bookstore application might be using the popular Model-View-Controller (MVC) architecture, but the models have now moved into microservices and the controller simply uses the REST APIs of the microservices to request the models and perform updates to them. Notably, the individual microservices can scale independently to handle varied load.
The next problems you might encounter have to do with using a single database. Let's say you get so many requests for reviews that you scale your reviews service up to 100 instances, with each instance making connections to that single database. The load is so high on the database that it slows down. Not only are your reviews affected, but now no one can place orders or browse your store either. In other words, one service misbehaving has taken down your whole application. To mitigate that risk, you decide to give each microservice its own database, and incidentally those databases can scale up independently as well. Let's review the architecture:
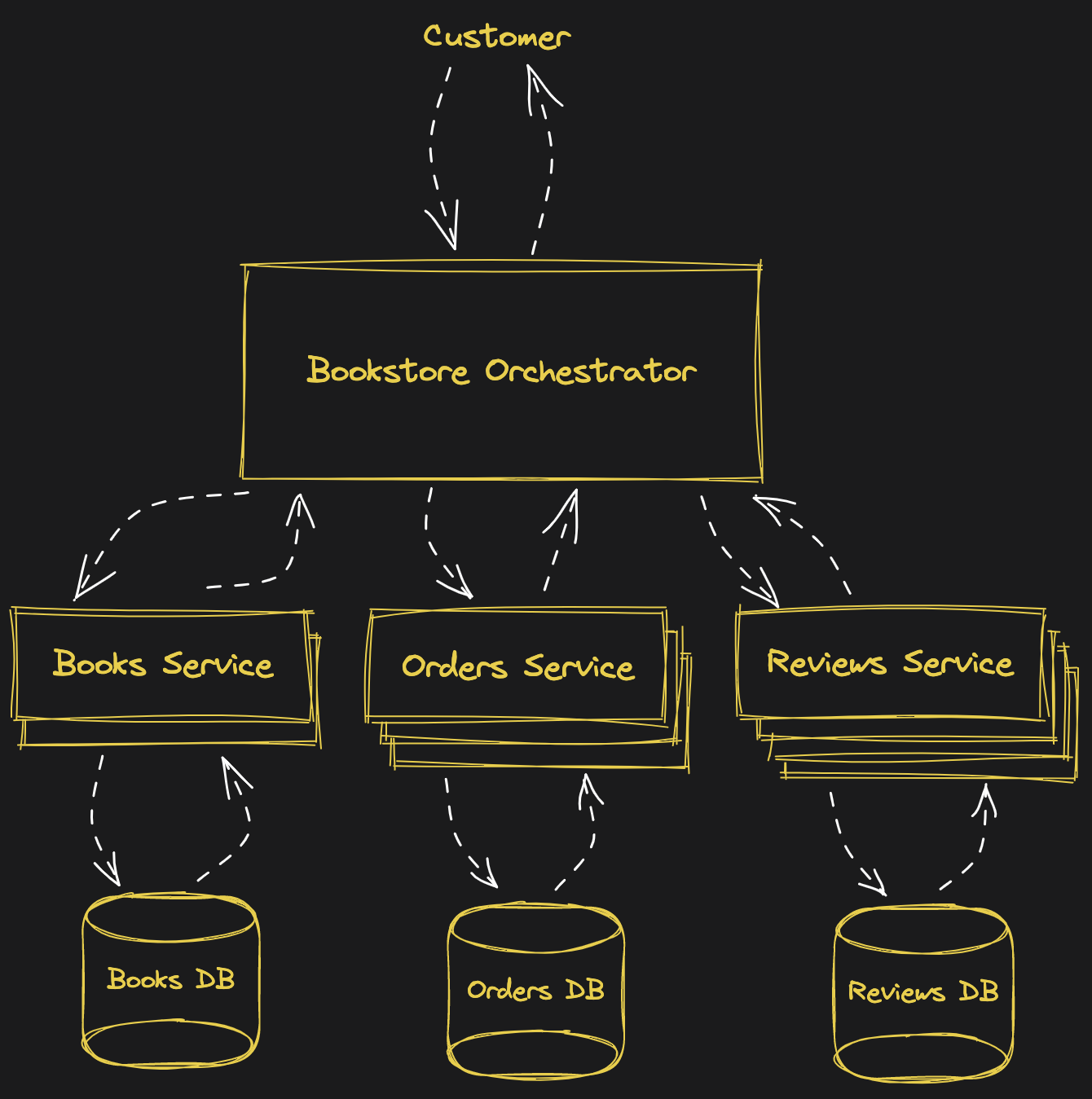
Your business is really taking off, and your customers want a mobile application. Your customers are split between iOS and Android, so you have to support both of them. Also, you hired some people to start updating your book inventory, and they don't know anything about SQL, so you can't have them run manual SQL queries like you've been doing so far. You decide to create an admin application for them. How do things look now?
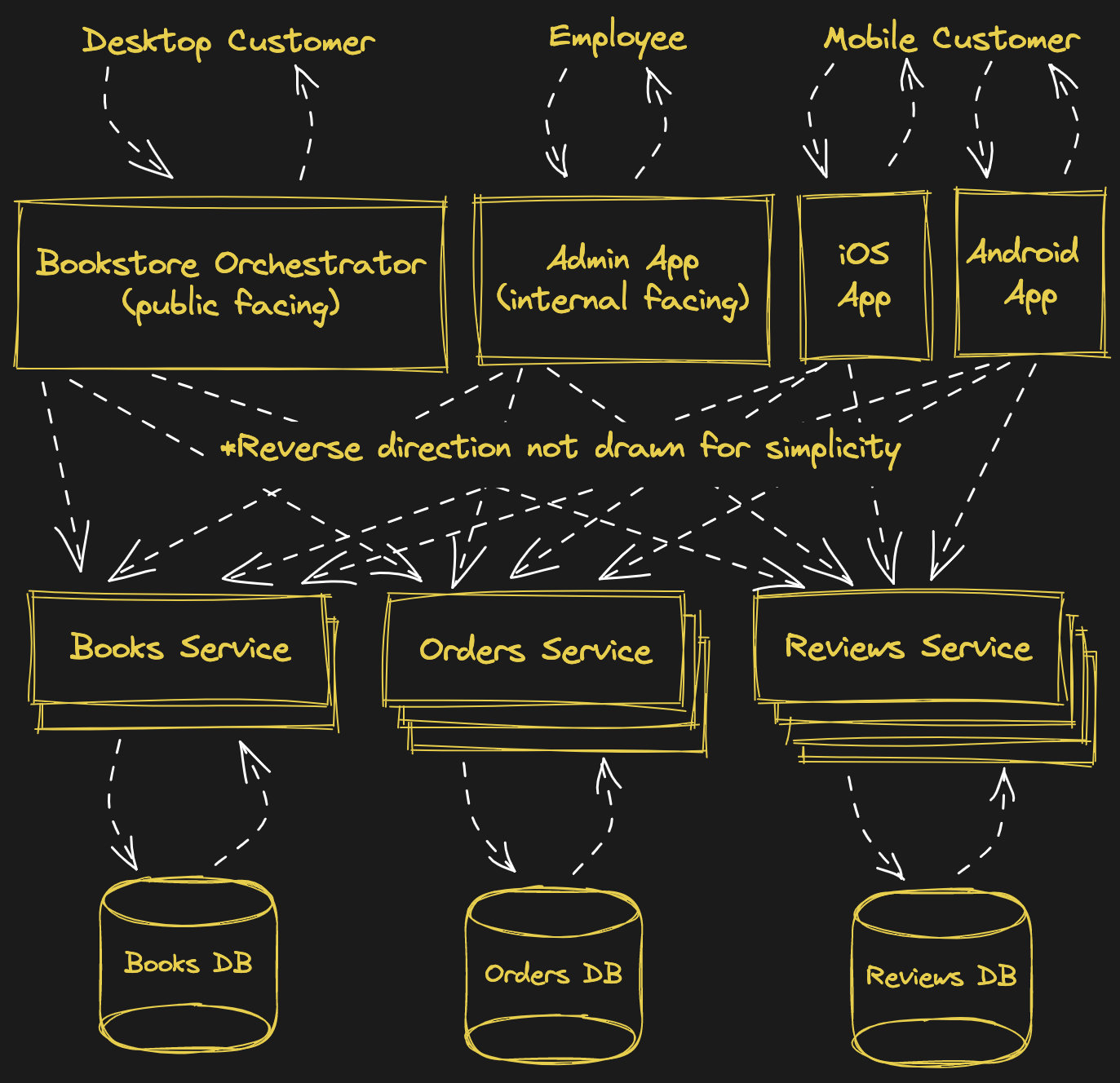
The diagram is starting to get messy, but there's nothing inherently wrong here. Sure, there are a lot of arrows, but those microservices can scale up as large as we need them to. However, we now have at least 4 different frontends, at least 3 of which are likely written in different frameworks. Each of these frontends is connecting directly to the microservices, meaning the REST API contracts that those services expose is now bound to those frontend applications. The more references the frontends start to make to the microservices, the riskier it gets to change the API contract. You might have dozens or even hundreds of locations to track down and update.
You could solve this problem by introducing a huge service orchestration layer that all the frontends communicate with. That would certainly reduce the number of overlapping arrows:
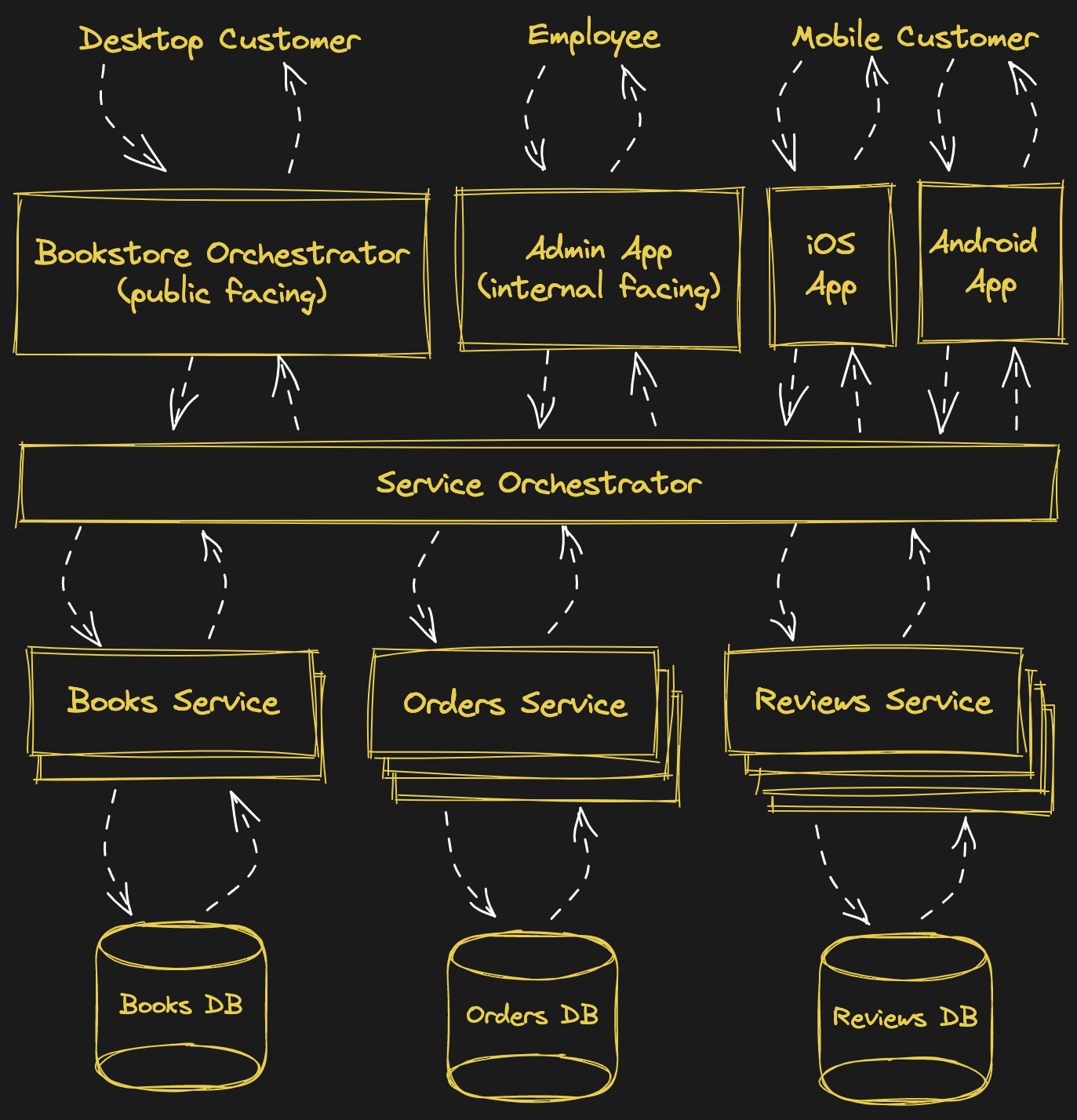
But inevitably the desktop application, mobile applications, and admin application will all need to support diverse views, so the service orchestrator will have to support a bloated set of frontend contracts. Furthermore, you now have a single point of failure again since critical errors in that service layer could affect all of your frontend applications.
BFFs in a nutshell
What if each frontend application had its own dedicated service orchestrator? The orchestrator could function as a presenter, exposing very stable, frontend-specific API contracts consisting of simple formatted strings and booleans. Heck, every page of the desktop application or screen of the mobile applications could have their own dedicated and highly-specialized API endpoint. We call such an API contract a View Model and such a service orchestrator a Backend for Frontend or BFF.
It looks like this:
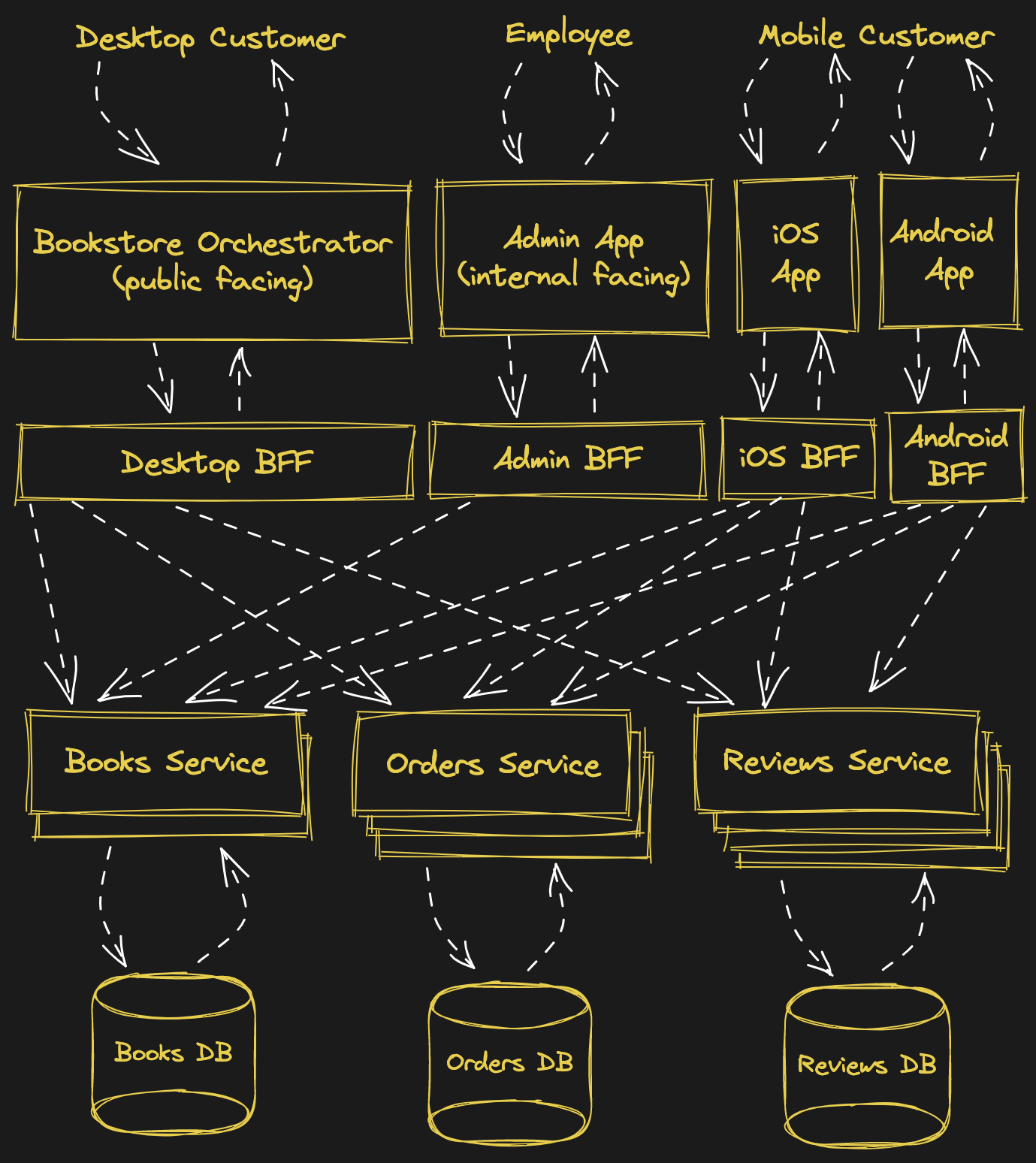
Notice in this example that the Admin BFF only connects to the Books Service. The Admin App doesn't care about orders or reviews right now, so its
BFF doesn't need to orchestrate data from those services.
Now, let's say the Books Service data model used to support only a single author:
data class Book(
val title: String,
val isbn: String,
val author: String
)
We realize that some books have multiple authors, so we change this contract to support a list of authors:
data class Book(
val title: String,
val isbn: String,
val author: List<String>
)
Oh, no! We wrote our 4 frontend applications to only support a single author.
Our user interface design and all related code depends on there only being one
author. Before BFFs, we'd have quite a few changes to make all over each
application. With BFFs, we just need to update each BFF that references the
books endpoint of the Books Service to pick the 0th item of the new authors
array. Now our frontends still work as expected and it buys us time to build new
designs for each application to support the display of multiple authors
(assuming we decide to support such a change). When we're good and ready for
that feature, we can update our BFFs again to send multiple authors through our
View Models. BFFs bought us flexibility, isolation, and the time we needed to
defer a decision.
The BFF architectural pattern is beautifully simple in concept but very liberating, especially at scale where multiple teams are working on interlocking software. But you don't have to have multiple desktop and mobile applications to reap the benefits of the BFF pattern. The cognitive simplicity created from dedicated View Model contracts plus the ease in testability makes the pattern worth exploring at smaller scales too.
Published May 18, 2023 by Jacob Chappell
